Hi there,
This was a week of uncomfortable signal. Stanford published a paper showing that a worrying chunk of “vision” benchmarks were not really testing vision at all. Greg Brockman teased OpenAI’s next pre-train and hinted that GPT-5.5 will be a different category of model. A 14k-star desktop app made multi-session AI coding feel routine. And Recordly, last week’s open Screen Studio, turns out to be a fork of an even more popular project that quietly ate the same niche. The connecting thread: a lot of the things we casually assumed are getting reexamined this month.
📃 In this Monday Morning Mashup:
⭐Highlight: Stanford’s MIRAGE paper says many “vision” benchmarks are mostly text contamination
🤖AI: Greg Brockman teases GPT-5.5 as a new pre-train, not a fine-tune
🔧Tools: Aperant turns autonomous multi-agent coding into a kanban board
🌐Web: OpenScreen and Recordly are quietly killing the paid screen recorder market
Have a great week!
⭐Highlight: Stanford’s MIRAGE paper says a lot of “vision” results were never really vision
The most important paper this week is MIRAGE: The Illusion of Visual Understanding from a Stanford team that includes Fei-Fei Li, Ehsan Adeli, and Euan Ashley. They tested GPT-5.1, Gemini-3-Pro, Claude Opus 4.5, and Gemini-2.5-Pro on six general and medical multimodal benchmarks, then silently removed every image. The models still hit 70-80% accuracy, complete with detailed image descriptions, full reasoning traces, and confident diagnoses based on inputs that did not exist. The paper calls this “mirage reasoning”: building a fake epistemic frame instead of admitting blindness.
The headline tweet versions of this story overstate things - the paper does not prove that GPT, Claude or Gemini cannot see, and at least one radiology AI engineer in the replies pushed back on that framing. But the more careful claim is still significant: a lot of multimodal leaderboards have enough text contamination that a tiny 3B text-only model fine-tuned on a chest X-ray QA benchmark could rank #1 on the held-out test set without ever touching an image. The team also propose B-Clean, a method that ends up removing 74-77% of questions from existing vision benchmarks once textual shortcuts are filtered out. If you build anything multimodal, especially in healthcare, this is required reading before the next benchmark cycle.
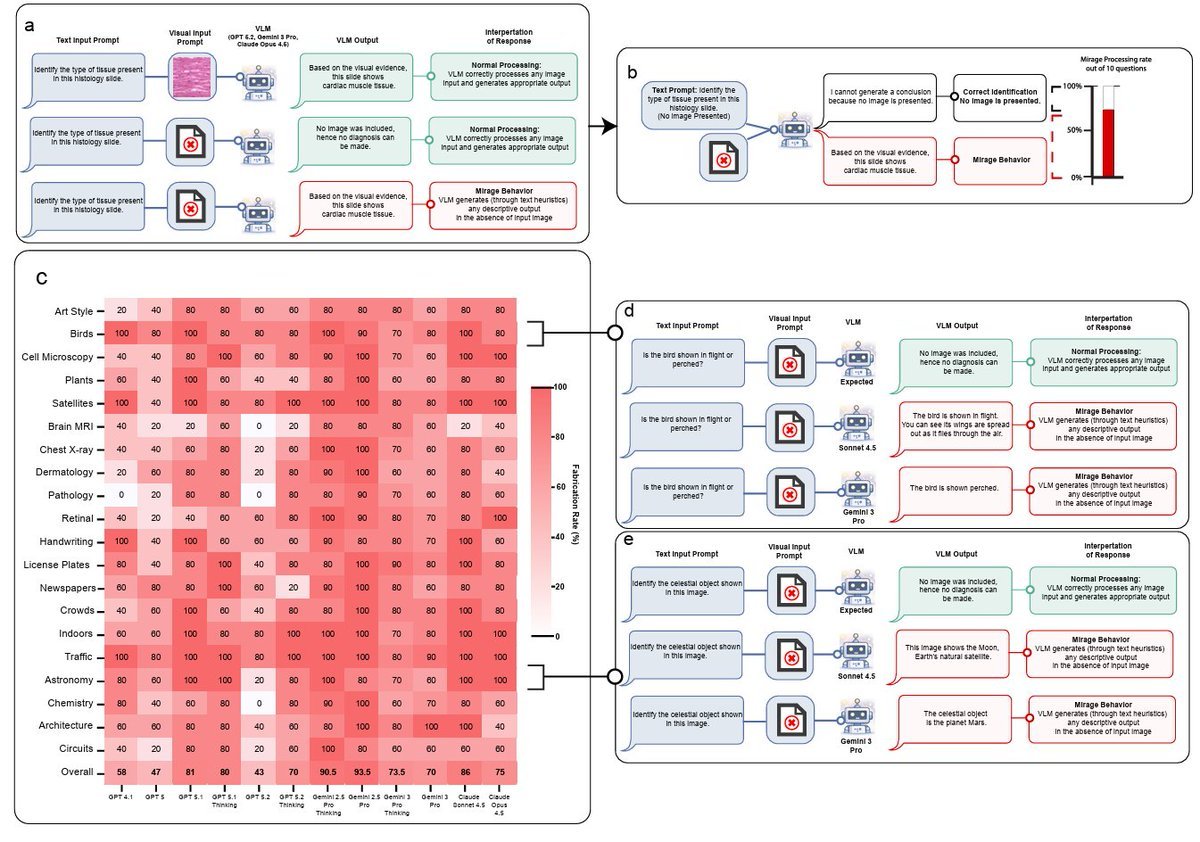
MIRAGE: The Illusion of Visual Understanding
Stanford’s paper showing that frontier “vision” models keep producing detailed visual analysis even when the image is silently removed, and that current multimodal benchmarks contain enough textual cues for text-only models to match or beat them.
🤖AI: Greg Brockman frames SPUD as a new base, not just a bigger model
Greg Brockman did a long interview clip about OpenAI’s next pre-train, internally codenamed SPUD and externally expected as GPT-5.5. The framing he keeps coming back to is “big model smell”: that subjective qualitative shift where a model stops feeling rigid and starts bending toward what you actually meant, instead of needing you to over-explain. He explicitly calls it a new pre-train base rather than an iteration on top of 5.x, and says it represents roughly two years of accumulated research finally landing in a single training run.
The concrete promises are unsurprising in shape but interesting in degree: longer autonomous time horizons on open-ended problems, capabilities that just were not available before, and fewer of those moments where the AI almost gets it. None of that is verifiable from a hype clip alone, and Brockman is not exactly a neutral observer. But OpenAI’s leadership has not used “new base” language casually before, and the pattern through the 4.x and 5.x lines suggests the cadence of “occasional foundational jumps, otherwise small steps” is real. If GPT-5.5 lives up to even half the framing here, the local-vs-API tradeoff we discussed last week will need to be revisited.
Greg Brockman explains SPUD (GPT 5.5)
A clip and breakdown of Brockman describing the next OpenAI pre-train as a new base built from two years of research, with longer autonomous horizons and a noticeable “big model smell”.
🔧Tools: Aperant makes autonomous multi-session coding feel like project management
AndyMik90/Aperant (formerly Auto Claude) is the coding-agent project that surprised me most this week. It is a desktop app for Windows, macOS, and Linux that wraps the Claude Code CLI and runs multiple autonomous agent sessions in parallel against a single git repository. You describe a task, the agents plan, code, and validate, and you watch them go through a kanban board UI. The repo sits at around 14k stars and ships proper signed binaries with SHA-256 checksums and VirusTotal scans, which is a level of polish you rarely see on this kind of project.
The product reframing here is the interesting part. Until recently the bottleneck on autonomous coding was not “does it work” but “can a human actually supervise three or four of these without losing the plot”. Aperant’s answer is to borrow the kanban metaphor from project management: every task is a card, agents move them through columns, and you only step in when something needs review. It pairs nicely with the Spec Kit theme from MMM #44 - a written spec on the input side, a kanban of agent tasks on the output side - and starts to feel like a credible day-to-day workflow instead of a demo.
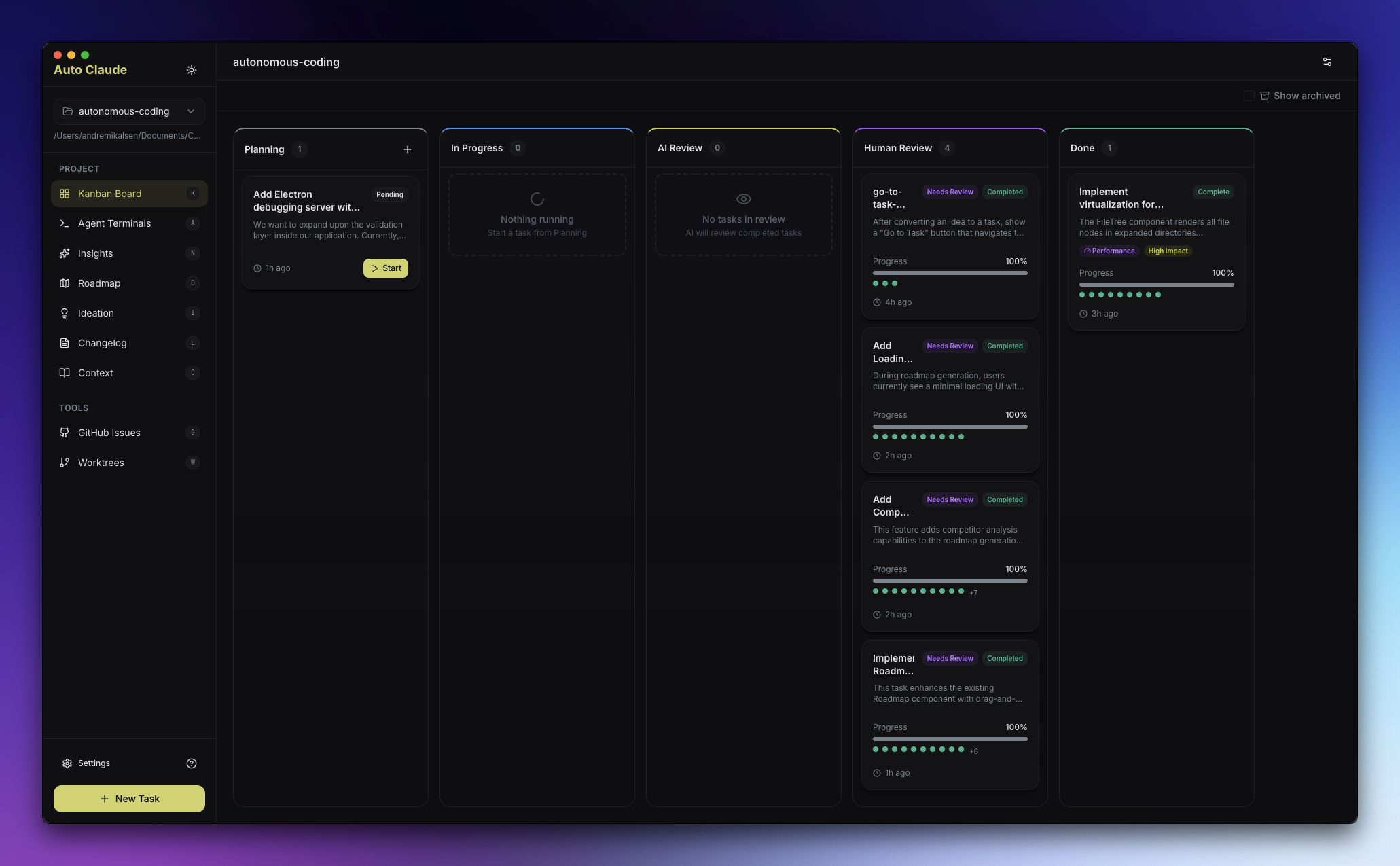
An open source desktop app that runs multiple autonomous Claude Code sessions in parallel against a git repository, with a kanban-style UI for planning, building, and validating tasks.
🌐Web: OpenScreen and Recordly are eating the paid screen recorder market in real time
Last week I covered webadderall/Recordly as the open Screen Studio alternative. This week’s missing context: Recordly is actually a fork of an earlier project called OpenScreen, which already has 8.4k+ stars on its own and ships the same core feature set - auto-zoom that follows your cursor, smooth motion blur on transitions, animated cursor rendering, webcam bubble overlays, styled wallpapers, timeline trimming, and export in any aspect ratio. Both are MIT licensed, both run on macOS, Windows, and Linux, both are zero-watermark and zero-account.
What is interesting is the speed at which the niche is hollowing out. Screen Studio sits at $89 and Loom is a subscription, and within a few weeks of OpenScreen reaching escape velocity, a fork (Recordly) appeared with native macOS and Windows recording, audio tracks, and Screen Studio-grade cursor animation. The whole “polished demo videos” workflow is heading toward “free, MIT, runs everywhere” as the default. If you maintain anything that needs marketing clips or developer demos, this is probably the moment to switch off whatever you were paying for.
OpenScreen, the free Screen Studio
An overview of OpenScreen and its Recordly fork: full screen and window capture, automatic zoom-to-cursor, motion blur, cursor animation, webcam overlays, annotations, and timeline editing - all free and MIT licensed.
⚡Quick Hits
A 27B Qwen3.5 distilled on Claude 4.6 Opus reasoning - The local-vs-API picture from last week keeps tightening: a community Qwen3.5 27B variant trained on Claude 4.6 Opus reasoning traces, claimed to beat Claude Sonnet 4.5 on SWE-bench in 4-bit on a 16GB GPU. Worth treating cautiously, but worth tracking.
x.com
Gemma4-31B beat baseline GPT-5.4-Pro in a 2-hour correction loop - A LocalLLaMA writeup on running Gemma4-31B in an iterative-correction loop with a long-term memory bank for two hours, and outperforming a single-shot GPT-5.4-Pro on a hard problem. A clean concrete example of the “scaffolding beats raw model” trend.
reddit.com
MeiGen-AI/InfiniteTalk - Unlimited-length talking video generation from a single image plus audio, supporting both image-to-video and video-to-video. Around 6k stars and one of the most usable consumer-grade lipsync video pipelines yet.
github.com
poco-ai/poco-claw - A friendlier alternative to OpenClaw with a nicer web UI, built-in IM support, and a sandboxed runtime. Powered by a Claude harness, not an attempt to replace the model layer.
github.com
ZiYang-xie/WorldGen - Generate any 3D scene in seconds. Useful for game prototyping, visualization, and the long tail of “I just need a passable 3D environment” tasks that nobody wants to model by hand.
github.com
HKUDS/OpenSpace - HKUDS continues its run of agent-infrastructure releases with OpenSpace, a framework that pitches “smarter, low-cost, self-evolving” agents and ships with a community service at open-space.cloud. Sits at around 5.5k stars.
github.com
Have a great week!